
As the patents on many drugs, which have been
launched in the 1990s, will soon expire, the pharmaceutical industry
finds itself at a turning point in its evolution, particularly as far as
research and development are concerned. As the pipelines of new
products are shrinking, the exposure of many companies is increasing.
This will surely hurt revenue in mid and long term. Further pressure
comes from an increasingly turbulent economy, shareholders, greater
regulatory burden and rallying operating costs, not to mention growing
R&D costs. It is the high clinical development costs, in conjunction
with shrinking drug discovery rates that are leading to a decline in
the productivity in the pharmaceuticals industry. Moreover, during the
last decade, R&D productivity has decreased. But even though
emerging technologies have enabled companies to develop multiple
parallel options, and to test numerous compounds in early stages, such
techniques are effective only when there exist databases of candidates
as well as drug evaluation criteria. An important improvement is
expected in establishing new methods for identifying unwanted toxic
effects in early development phases, as well as reducing the late-stage
failure rate. Bio-informatics and biomarkers are expected to play an
important role.
However, independently of new technologies, and in
order to adapt, the pharmaceutical industry must re-think its current
business model which appears to be unsustainable in a rapidly changing
and demanding market. Innovative medicines will be in demand, as the
need for more personalised treatment grows for an quickly growing and
fragmented population. In fact, as diagnosis methods improve, the need
for more personalised and focused drugs will be inevitable.
Pharmaceutical companies must transition from the old block-buster model
to a more fragmented and diversified offering of products. It appears,
therefore, that the economical sustainability of the pharmaceutical
industry hinges on innovation.
A major concern shared by all drug manufacturers is
that of drug toxicity. A candidate molecule under investigation must be
validated on animals before authorisation for trials in humans is
granted. If these preclinical studies show good results, clinical trials
with healthy volunteers follow. These have the scope of studying drug
efficacy and excluding the presence of toxic effects. Following numerous
trials on patients with the targeted disease provide a statistical
description of the drug efficacy. There exist essentially two approaches
to drug toxicity determination: knowledge-based and the QSAR
(Quantitative Structure Activity Relationship) rule-based models, which
relate variations in biological activity and molecular descriptors.
Evidently, any expert of rule-based system will see its efficacy bounded
by the quality and relevance of the employed rules. Because of the
inability to predict successfully drug toxicity, drug manufacturers
report billion-dollar losses every year.
We wish to formulate a conjecture in relation to drug
toxicity: the toxic effects of a molecule are proportional to its
complexity. In other words, we suggest that a more complex molecule has
greater potential to do damage and over a broader spectrum and that
higher complexity may also imply greater capacity to combine with other
molecules. The underlying idea is to use complexity as a ranking and
risk-stratification mechanism for molecules.
Over the last decade, Ontonix has been developing and
validating a novel approach to measuring complexity. The metric is
function of structure, entropy, data granularity and coarse-graining. It
has been used successfully as an innovative risk-stratification and
crisis-anticipation system in economics, medicine and engineering. The
metric possesses the following properties:
-
The existence of a lower and upper bound. The upper bound is known as critical complexity.
-
In the vicinity of its lower complexity bound, a generic dynamic system behaves in deterministic fashion.
-
In the vicinity of its critical complexity, a
system possesses a very high number of potential behavioral modes and
spontaneous mode-switching occurs even in the presence of injection of
very small amounts of energy.
-
A large number of components is not necessary
to lead to high complexity. Systems with a large number of components
can be considerably less complex than systems with a very small number
of components. In essence, complicated does not necessarily imply
complex.
Based on molecular modelling and molecular simulation
techniques (Monte Carlo Simulation), one may readily measure the
complexity of compounds and use this measure to classify and rank them.
In other words, we suggest to use complexity as a “biomarker”. A simple
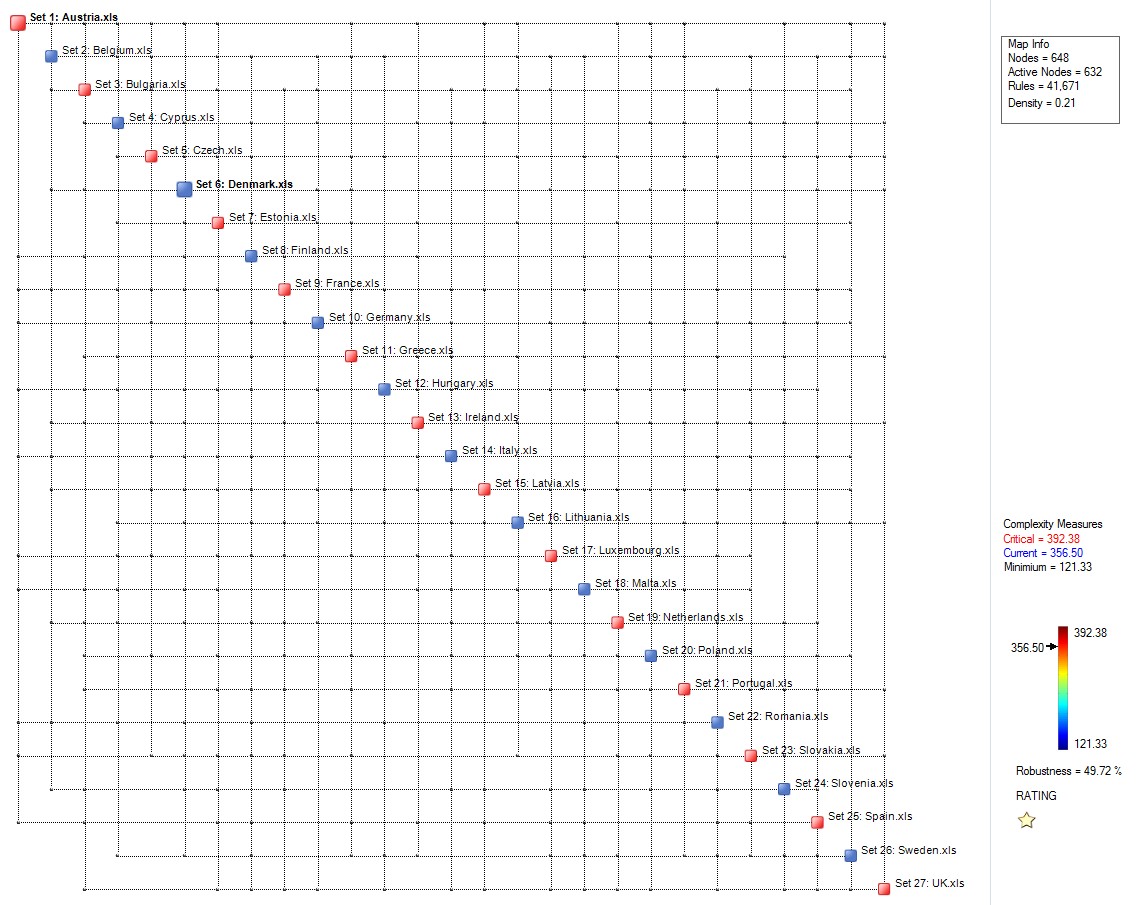
example of the concept is illustrated below, where two so-called Process
Maps are shown. Each map is determined automatically by OntoSpace™.
Such maps represent the structural properties of a given system, whereby
relevant parameters are aligned along the diagonal and are linked by
means of connectors (blue dots) which correspond to significant rules.
Critical parameters – shown in red – correspond to hubs. The map on the
left corresponds to a system with 94 rules and has a complexity of 28.4.
The one on the right exhibits 69 rules and a complexity of 19.2.
Supposing that both maps correspond to two candidate drugs for the same
target disease, the one of the right could correspond to a potentially
less toxic candidate. As mentioned, this is a conjecture and needs to be
verified.

Clearly, the logic is that if one can perform a given
task with a less complex solution, that is probably a better solution.
However, we also suggest that substances which function in the proximity
of their corresponding critical complexities are globally less robust
and, potentially, more toxic. Therefore, a higher value of complexity
does not necessarily imply a worse alternative – it is ultimately the
relative distance to the corresponding critical complexity which may
turn out to be a better discriminant.
























{kind=link}
{kind=link}